In mendix you can define indexes on your entities. You do this in the indexes tab of the Properties of entity window as illustrated in this screenshot.
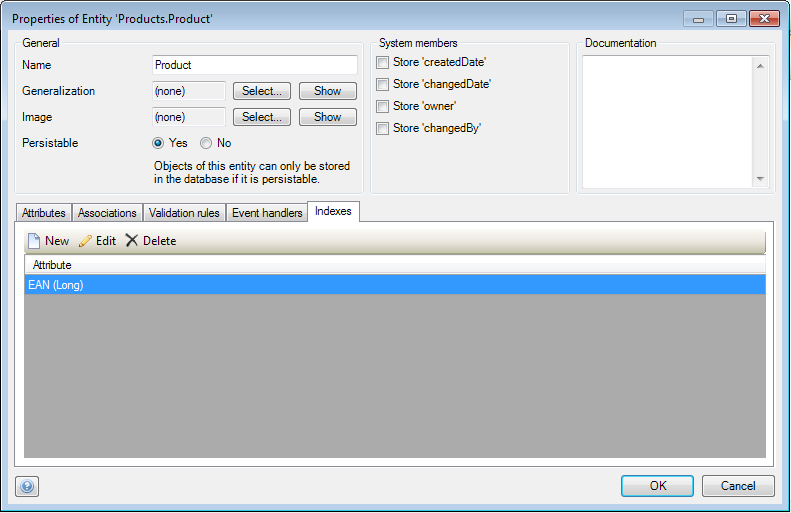
Please do not forget to create indexes on columns that you often filter on in your xpath expressions.
Here is a small example to see the impact of an index on the performance of your database.
First lets create a table with some test data:
create table t1 as
select uuid_in( md5((random()::text) || ((now())::text) || (random()::text))::cstring) as id
, md5(random()::text) as s1
, md5(random()::text) as s2
, n1
, n2
from generate_series(1,10000) as n1
, generate_series(1,100) as n2;
alter table t1 add constraint t1_pk primary key (id);
I'm using psql to do this directly on the database. Psql has some commands to enable timing, and turn of pagination.
\timing on
\pset pager
Now lets see what happens when we do a simple query on this table:
mx=# explain analyze select * from t1 where n1 = 10 and n2 = 10;
QUERY PLAN
---------------------------------------------------------------------------------------------------
Seq Scan on t1 (cost=0.00..30385.00 rows=1 width=90) (actual time=0.555..180.105 rows=1 loops=1)
Filter: ((n1 = 10) AND (n2 = 10))
Total runtime: 180.186 ms
(3 rows)
Time: 182.618 ms
Without an index, the database is going to scan every record stored in the table. For every record it is going to execute the filter as specified in the where clause. In this example, running the query would take 180 milliseconds.
What happens if you create indexes on columns n1 and n2?
create index t1_n1 on t1(n1);
create index t1_n2 on t1(n2);
When you now run the same query, the results are as follows:
mx=# explain analyze select * from t1 where n2 = 10 and n1 = 10;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on t1 (cost=187.98..285.33 rows=25 width=88) (actual time=12.728..12.745 rows=1 loops=1)
Recheck Cond: ((n2 = 10) AND (n1 = 10))
-> BitmapAnd (cost=187.98..187.98 rows=25 width=0) (actual time=12.511..12.511 rows=0 loops=1)
-> Bitmap Index Scan on t1_n2 (cost=0.00..93.86 rows=5000 width=0) (actual time=8.936..8.936 rows=10000 loops=1)
Index Cond: (n2 = 10)
-> Bitmap Index Scan on t1_n1 (cost=0.00..93.86 rows=5000 width=0) (actual time=0.214..0.214 rows=100 loops=1)
Index Cond: (n1 = 10)
Total runtime: 12.938 ms
(8 rows)
Time: 17.068 ms
The total time to run the query has dropped from 180 milliseconds to 12 milliseconds. The actual performance improvement depends on caching and other parameters like hardware. But you can clearly see that the PostgreSQL performance optimizer chooses a different plan to execute the query. It first searches for the applicable records in the indexes, before it gets the records from the table. This results in a huge performance win.